
Last Friday, we had a major outage at Flownative Beach, which took around 30 customer projects offline for about an hour and a half. We would like to explain transparently what happened, how we dealt with it and what measures we are planning for the future.
tl;dr There was a major outage of cloud servers at Hetzner. We were also affected, as a result of which a third of the resources in one of our Beach clusters failed. The automatic repair came to nothing because no new servers were available in Nuremberg. We temporarily moved the affected projects to Helsinki and were able to restore normal conditions on Monday. We are now working on a more resilient infrastructure with more buffers and our own bare-metal servers.
What happened?
At 02:45 am, our monitoring suddenly reported status code 503 for dozens of websites. Karsten was automatically notified and was on the computer within a few minutes. After the initial analysis, it was clear that this was bigger. At 03:15, Robert was also on the conference call.
The cause was quickly found, but all the more sobering: numerous virtualization nodes at Hetzner had failed - the physical machines on which our virtual servers run. Around a third of our cluster was affected, the servers were simply gone.
Normally, our Kubernetes cluster reacts to such failures fully automatically: it starts new servers within seconds and moves the affected workloads to them. This is one of the great advantages of cloud-native infrastructure. Only this time it didn't work.
Resource unavailable
The reason: no more new servers could be ordered in Nuremberg. The Hetzner API consistently reported "resource unavailable". We were unable to start any new servers - either automatically or manually.
After some back and forth, we performed a triage: Testing and staging instances were shut down to free up resources for production websites. This gave us some breathing space, but did not solve the fundamental problem. Some databases also had no more space in the cluster.
Spontaneous move to Helsinki
Over the course of the morning, we developed an ad hoc solution: we quickly expanded our cluster to servers in Helsinki. This was not trivial - not all server types were available and the setup took time. But by midday, all affected Beach instances were up and running again, albeit with the minor flaw that parts of our infrastructure were now 1,500 kilometers apart.
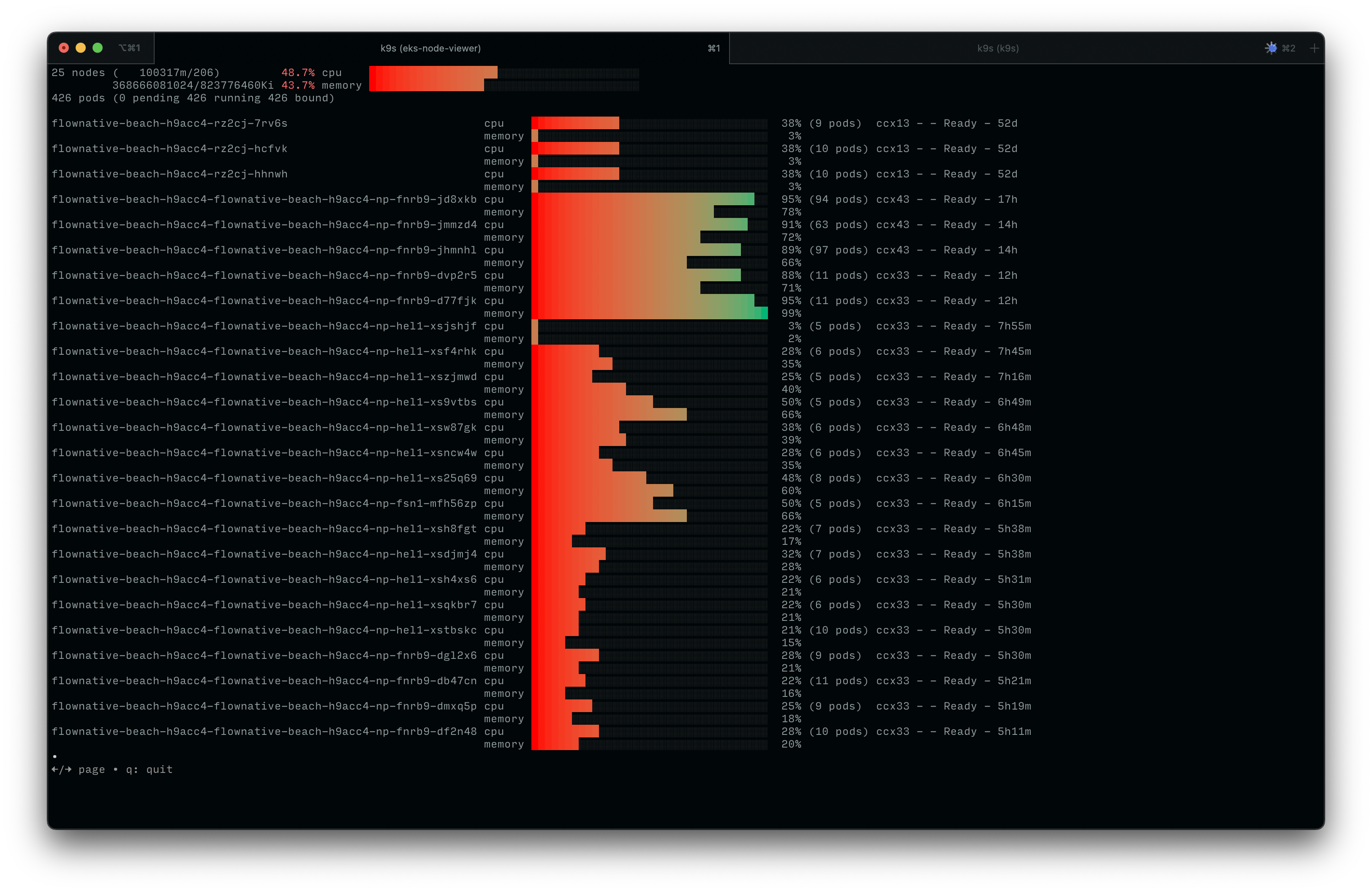
Numerous cluster nodes are now located in Helsinki|Screenshot: Flownative Team
We used the weekend to stabilize the new multi-region setup and adjust our monitoring. There were still no servers available to order in Nuremberg, and the Falkenstein site was also fully booked with a few exceptions.
Back home
New server types were only available again on Monday morning. We immediately reserved large quantities of very large virtual servers - well in excess of our actual requirements. Over the course of Monday, we were able to transfer all Beach instances back to Nuremberg during ongoing operations.
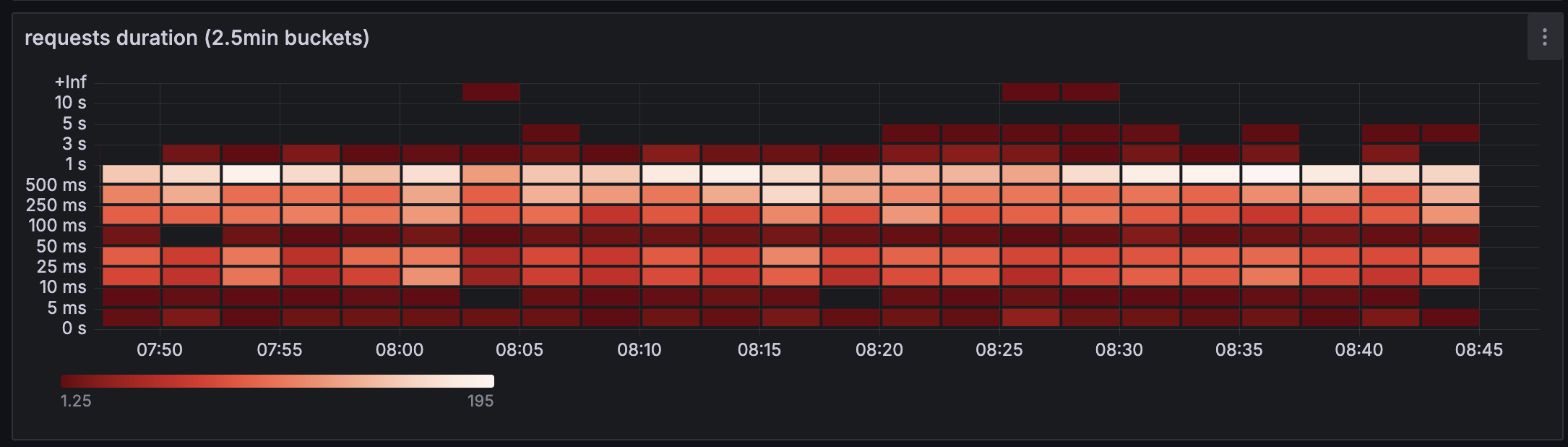
Requests had very different durations while part of the cluster was running in Helsinki|Screenshot: Flownative Team
During the time in Helsinki, there were latency problems with some websites due to the geographical distribution. We did prove unplanned that multi-region deployments work with Beach - just not in the way we had imagined.
What have we learned from this?
First of all: despite the very unpleasant effects, our team worked really well. The collaboration was focused and effective, and we managed to find creative solutions under pressure. If we can even say that at this point: We are also a little proud of that.
But of course we are only pleased with this unplanned exercise to a limited extent. The impact on our customers was considerable and we haven't experienced anything like this for years.
We have no doubts about Hetzner as a partner. Hetzner has been an important player in the German hosting market for many years and is also known for its professionalism, despite its relatively low prices. But there seems to be a bit of a crunch at the moment. We know from the Hetzner forum that they are struggling with supply bottlenecks for AMD servers and at the same time have to meet a sharp increase in demand - also because many companies are switching from US clouds to German providers due to GDPR concerns. What we definitely lacked was transparent communication about the availability of resources. We are really flexible in this respect and can also work with larger or smaller server types. However, we have to be able to rely on the fact that we can get servers at all.
» We continue to see a sharp rise in demand, particularly from the professional environment, which requires significantly more large (dedicated) instances and also calls them up dynamically. Accordingly, both volatility and the need for systems have increased significantly. But I am optimistic that we will be able to cope with this and scale our production accordingly. «
A side note: Other large hosting providers also have this resource problem. In our cluster in the Open Telekom Cloud, we were unable to scale up the Kubernetes cluster more than once because there were no more servers in the entire availability zone. And Telekom only has 3 zones in the whole of Germany.
Our strategy for the future
- More buffer: We are now only using around 20% of our reserved capacity. The rest serves as a buffer for such situations.
- Bare-metal servers: We have been evaluating the possibility of integrating our own physical servers into our clusters for several weeks now. We can dimension these larger and have to scale less dynamically.
- Diversification: We are keeping our eyes open for additional providers that meet our data protection and technical quality requirements.
The goal of digital sovereignty
Two years ago, we decided to switch from Google Cloud to Hetzner. The reason: long-term GDPR compliance and digital sovereignty. We still fully stand by this decision.
Yes, we probably wouldn't have had this particular problem with Google. But we would have had other problems - legal, ethical and dependence on a US company whose priorities can change at any time due to political directives from the White House.
The road to digital sovereignty is sometimes a rocky one. But we believe it is the right path - for us, for our customers and for a free Internet.
Thank you for your trust
To all affected customers: We are truly sorry for the inconvenience. We know how critical your websites are to your business.
Thank you for your understanding and constructive feedback over the past few days. Your feedback helps us to make Beach even better.
If you have any questions or would like to talk about your experiences, please get in touch. We look forward to hearing your thoughts - on incident management, our infrastructure strategy or digital sovereignty in general.
Stay afloat! 🏄♂️
Your Flownative team