
Am vergangenen Freitag hatten wir einen größeren Ausfall bei Flownative Beach, der etwa 30 Kundenprojekte für rund anderthalb Stunden offline nahm. Wir möchten euch transparent erklären, was passiert ist, wie wir damit umgegangen sind und welche Maßnahmen wir für die Zukunft planen.
tl;dr Bei Hetzner gab es einen größeren Ausfall von Cloud-Servern. Wir waren davon auch betroffen, wodurch ein Drittel der Ressourcen in einem unserer Beach-Cluster ausfiel. Die automatische Reparatur lief ins Leere, weil keine neuen Server in Nürnberg verfügbar waren. Wir haben die betroffenen Projekte temporär nach Helsinki verschoben und konnten am Montag den Normalzustand wiederherstellen. Wir arbeiten jetzt an einer resilienteren Infrastruktur mit mehr Puffer und eigenen Bare-Metal-Servern.
Was ist passiert?
Um 02:45 Uhr meldete unser Monitoring plötzlich Statuscode 503 für dutzende Websites. Karsten wurde automatisch benachrichtigt und war innerhalb weniger Minuten am Rechner. Nach der ersten Analyse war klar: Das hier ist größer. Um 03:15 Uhr war Robert per Konferenz-Schaltung auch mit dabei.
Die Ursache war schnell gefunden, aber umso ernüchternder: Bei Hetzner waren zahlreiche Virtualisierungs-Nodes ausgefallen – die physischen Maschinen, auf denen unsere virtuellen Server laufen. Etwa ein Drittel unseres Clusters war betroffen, die Server waren schlichtweg weg.
Normalerweise reagiert unser Kubernetes-Cluster auf solche Ausfälle vollautomatisch: Innerhalb von Sekunden startet er neue Server und verschiebt die betroffenen Workloads dorthin. Das ist einer der großen Vorteile von Cloud-Native-Infrastruktur. Nur diesmal funktionierte das nicht.
Resource unavailable
Der Grund: In Nürnberg waren keine neuen Server mehr bestellbar. Die Hetzner-API meldete konsequent "resource unavailable" zurück. Wir konnten keine neuen Server starten – weder automatisch noch manuell.
Nach einigem Hin und Her haben wir eine Triage vorgenommen: Testing- und Staging-Instanzen wurden abgeschaltet, um Ressourcen für Production-Websites freizugeben. Das verschaffte uns etwas Luft, löste aber nicht das grundlegende Problem. Auch einige Datenbanken hatten keinen Platz mehr im Cluster.
Spontaner Umzug nach Helsinki
Im Laufe des Vormittags entwickelten wir eine Ad-hoc-Lösung: Wir erweiterten unseren Cluster kurzerhand auf Server in Helsinki. Das war nicht trivial – nicht alle Servertypen waren verfügbar und die Einrichtung brauchte Zeit. Aber bis Mittag liefen alle betroffenen Beach-Instanzen wieder, wenn auch mit dem kleinen Schönheitsfehler, dass Teile unserer Infrastruktur nun 1.500 Kilometer auseinander lagen.
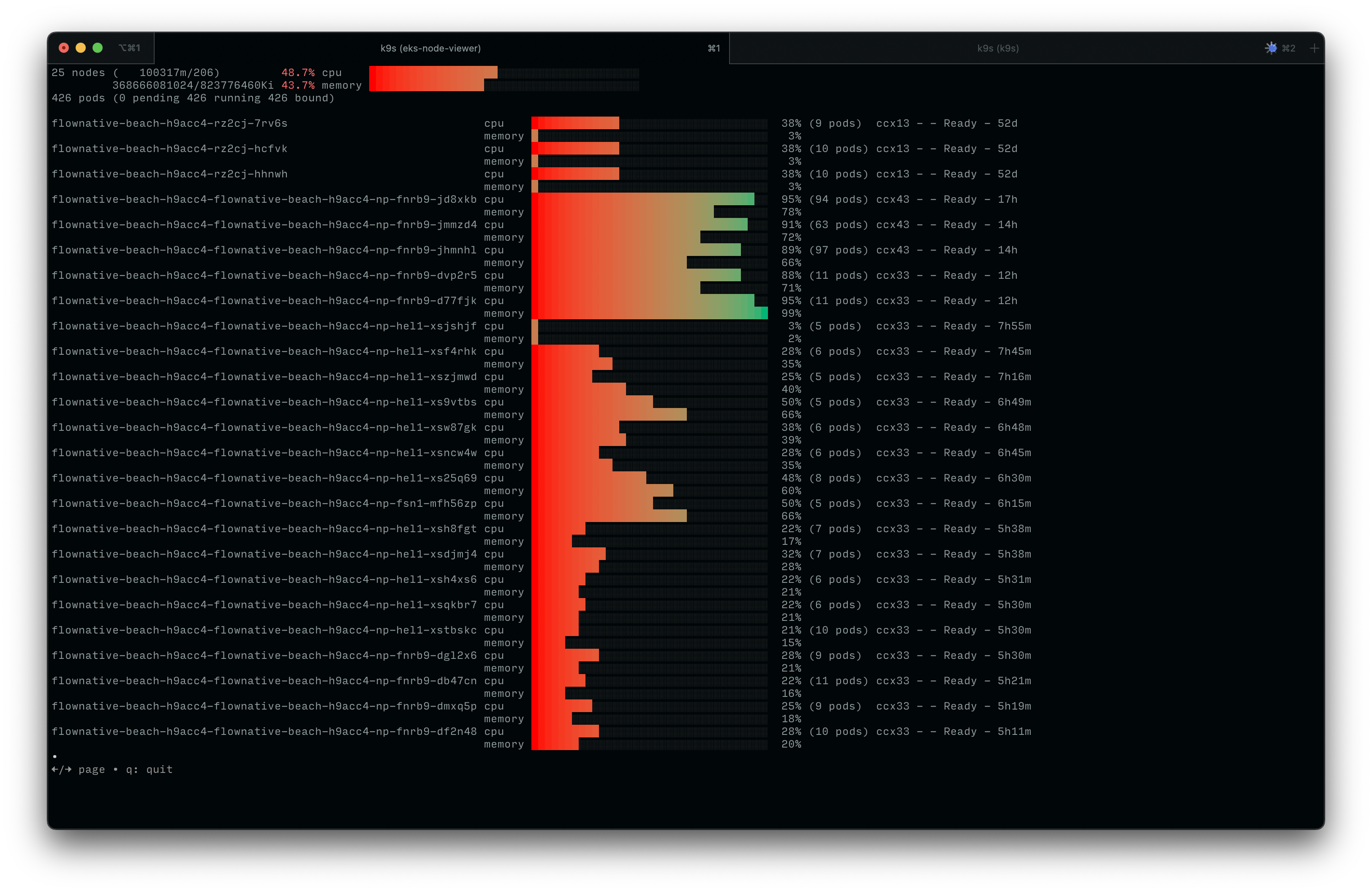
Zahlreiche Cluster-Nodes befinden sich zwischenzeitlich in Helsinki|Screenshot: Flownative Team
Das Wochenende nutzten wir, um das neue Multi-Region-Setup zu stabilisieren und unser Monitoring anzupassen. In Nürnberg waren weiterhin keine Server bestellbar, auch der Standort Falkenstein war bis auf kleine Ausnahmen ausgebucht.
Zurück nach Hause
Erst am Montagmorgen waren wieder neue Servertypen verfügbar. Wir haben direkt große Mengen an sehr großen virtuellen Servern reserviert – deutlich über unseren eigentlichen Bedarf hinaus. Im Laufe des Montags konnten wir alle Beach-Instanzen im laufenden Betrieb zurück nach Nürnberg transferieren.
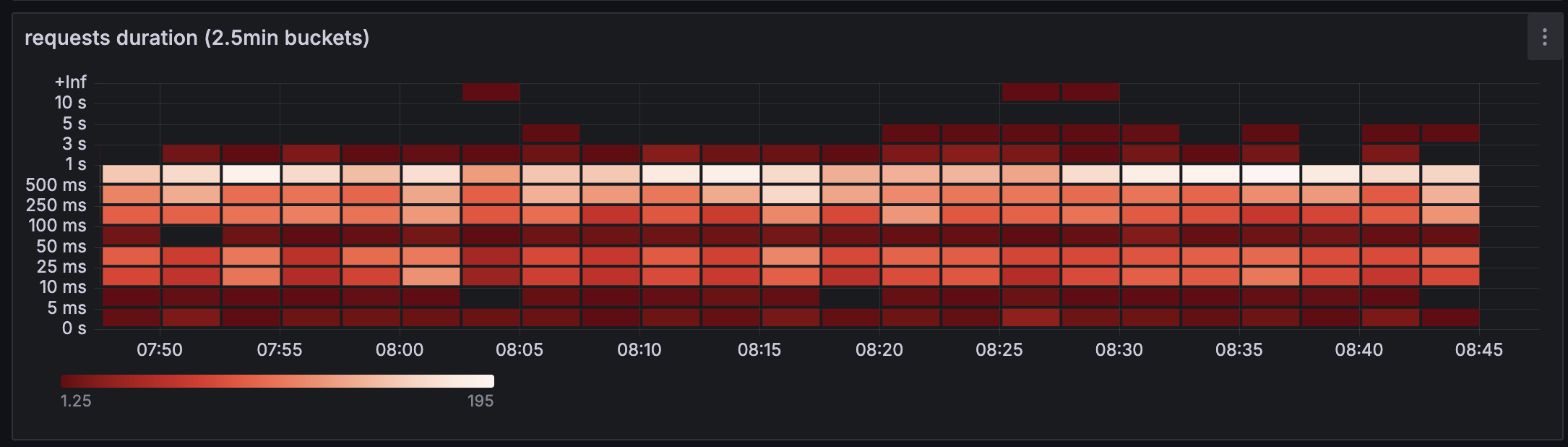
Requests hatten sehr unterschiedliche Dauer während ein Teil des Clusters in Helsinki lief|Screenshot: Flownative Team
Während der Zeit in Helsinki gab es bei einigen Websites Latenz-Probleme durch die geografische Verteilung. Wir haben zwar ungeplant bewiesen, dass Multi-Region-Deployments mit Beach funktionieren – nur eben nicht so, wie wir uns das vorgestellt hatten.
Was lernen wir daraus?
Zunächst mal: Trotz der sehr unangenehmen Auswirkungen hat unser Team wirklich gut funktioniert. Die Zusammenarbeit war konzentriert und effektiv, und wir haben es geschafft, unter Druck kreative Lösungen zu finden. Wenn wir das überhaupt an dieser Stelle sagen dürfen: Darauf sind wir auch ein bisschen stolz.
Aber natürlich freuen wir uns nur begrenzt über diese ungeplante Übung. Die Auswirkungen für unsere Kunden waren erheblich, und so etwas haben wir seit Jahren nicht mehr erlebt.
An Hetzner als Partner zweifeln wir nicht. Hetzner ist seit vielen Jahren ein wichtiger Player im deutschen Hosting-Markt und ist trotz der relativ günstigen Preise auch für seine Professionalität bekannt. Aber es scheint gerade etwas zu knirschen. Aus dem Hetzner-Forum wissen wir, dass sie mit Lieferengpässen bei AMD-Servern kämpfen und gleichzeitig eine stark gestiegene Nachfrage bedienen müssen – eben auch, weil viele Unternehmen wegen DSGVO-Bedenken von US-Clouds zu deutschen Anbietern wechseln. Was uns definitiv gefehlt hat, war transparente Kommunikation über die Verfügbarkeit von Ressourcen. Wir sind da wirklich flexibel und können auch mit größeren oder kleineren Servertypen arbeiten. Allerdings müssen wir uns darauf verlassen können, dass wir überhaupt Server bekommen können.
» Wir sehen weiterhin eine stark gestiegene Nachfrage, insbesondere aus dem professionellen Umfeld, welches deutlich mehr große (dedicated) Instanzen benötigt und diese auch dynamisch abruft. Dementsprechend ist sowohl die Volatilität als auch der Bedarf an Systemen signifikant gestiegen. Aber ich bin optimistisch, daß wir dem gewachsen sind und unsere Fertigung entsprechend skalieren können. «
Eine Notiz am Rande: Das Ressourcenproblem haben andere große Hoster durchaus auch. In unserem Cluster in der Open Telekom Cloud haben wir mehr als einmal den Kubernetes-Cluster nicht hochskalieren können, weil es in der gesamten Availability Zone keine Server mehr gab. Und die Telekom hat nur 3 Zonen in ganz Deutschland.
Unsere Strategie für die Zukunft
- Mehr Puffer: Wir nutzen jetzt nur etwa 20% unserer reservierten Kapazität. Der Rest dient als Puffer für solche Situationen.
- Bare-Metal-Server: Wir evaluieren bereits seit einigen Wochen die Möglichkeit, eigene physische Server in unsere Cluster einzubinden. Diese können wir größer dimensionieren und müssen weniger dynamisch skalieren.
- Diversifizierung: Wir halten die Augen nach weiteren zusätzlichen Anbietern offen, die unseren Ansprüchen an Datenschutz und technische Qualität genügen.
Das Ziel der digitalen Souveränität
Vor zwei Jahren haben wir uns entschieden, von Google Cloud zu Hetzner zu wechseln. Der Grund: Langfristige DSGVO-Konformität und digitale Souveränität. Zu dieser Entscheidung stehen wir weiterhin voll.
Ja, bei Google hätten wir vermutlich dieses spezielle Problem nicht gehabt. Aber wir hätten andere Probleme – rechtliche, ethische und die Abhängigkeit von einem US-Konzern, dessen Prioritäten sich jederzeit durch politische Richtlinien aus dem Weißen Haus ändern können.
Der Weg der digitalen Souveränität ist manchmal ein steiniger. Aber wir glauben, dass es der richtige Weg ist – für uns, für unsere Kunden und für ein freies Internet.
Danke für euer Vertrauen
An alle betroffenen Kunden: Es tut uns aufrichtig leid für die Unannehmlichkeiten. Wir wissen, wie kritisch eure Websites für euer Geschäft sind.
Danke für euer Verständnis und die konstruktiven Rückmeldungen in den letzten Tagen. Euer Feedback hilft uns, Beach noch besser zu machen.
Wenn ihr Fragen habt oder über eure Erfahrungen sprechen möchtet, meldet euch gerne bei uns. Wir sind gespannt auf eure Gedanken – zur Incident-Bewältigung, zu unserer Infrastruktur-Strategie oder zur digitalen Souveränität im Allgemeinen.
Stay afloat! 🏄♂️
Euer Flownative Team